So this is awkward. I’ve published Networks Demystified 7: Doing Citation Analyses before Networks Demystified 6: Organizing Your Twitter Lists. What depraved lunatic would do such a thing? The kind of depraved lunatic that is teaching this very subject twice in the next two weeks: deal with it, you’ll get your twitterstructions soon, internet. In the meantime, enjoy the irregular nature of the scottbot irregular.
And this is part 7 of my increasingly inaccurately named trilogy of instructional network analysis posts (1 network basics, 2 degree, 3 power laws, 4 co-citation analysis, 5 communities and PageRank, 6 this space left intentionally blank). I’m covering how to actually do citation analyses, so it’s a continuation of part 4 of the series. If you want to know what citation analysis is and why to do it, as well as a laundry list of previous examples in the humanities and social sciences, go read that post. If you want to just finally be able to analyze citations, like you’ve always dreamed, read on. 1
You’re going to need two things for these instructions: The Sci2 Tool, and either a subscription to the multi-gazillion dollar ISI Web of Science database, or this sample dataset. The Sci2 (Science of Science) Tool is a fairly buggy program (I’m allowed to say that because I’m kinda off-and-on the development team and I wrote half the user manual) that specializes in ingesting data of various formats and turning them into networks for analysis and visualization. It’s a good tool to use before you run to Gephi to make your networks pretty, and has a growing list of available plugins. If you already have the Sci2 Tool, download it again, because there’s a new version and it doesn’t auto-update. Go download it. It’s 80mb, I’ll wait.
Once you’ve registered for (not my decision, don’t blame me!) and downloaded the tool, extract the zip folder wherever you want, no install necessary. The first thing to do is increase the amount of memory available to the program, assuming you have at least a gig of RAM on your computer. We’re going to be doing some intensive analysis, so you’ll need the extra space. Edit sci2.ini; on Windows, that can be done by right-clicking on the file and selecting ‘edit’; on Mac, I dunno, elbow-click and press ‘CHANGO’? I have no idea how things work on Macs. (Sorry Mac-folk! We’ve actually documented in more detail how to increase memory – on both Windows and Mac – here)
Once editing the file, you’ll see a nigh-unintelligble string of letters and numbers that end in “-Xmx350m”. Assuming you have more than a gig of RAM on your computer, change that to “-Xmx1000m”. If you don’t have more RAM, really, you should go get some. Or use only a quarter of the dataset provided. Save it and close the text editor.
Run Sci2.exe We didn’t pay Microsoft to register the app, so if you’re on Windows, you may get a OHMYGODWARNING sign. Click ‘run anyway’ and safely let my team’s software hack your computer and use it to send pictures of cats to famous network scientists. (No, we’ll be good, promise). You’ll get to a screen remarkably like Figure 7. Leave it open, and if you’re at an institution that pays ISI Web of Science the big bucks, head there now. Otherwise ignore this and just download the sample dataset.
Downloading Data
I’m a historian of science, so let’s look for history of science articles. Search for ‘Isis‘ as a ‘Publication Name’ from the drop-down menu (see Figure 1) and notice that, as of 9/23/2013, there are 14,858 results (see Figure 2).
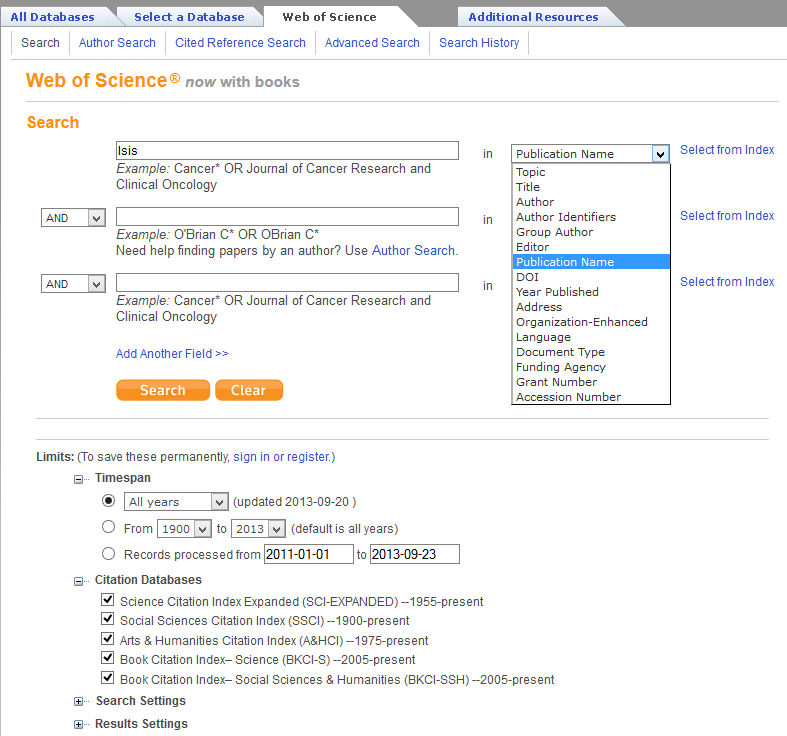
Figure 1: Searching for Isis as the name of a publication.
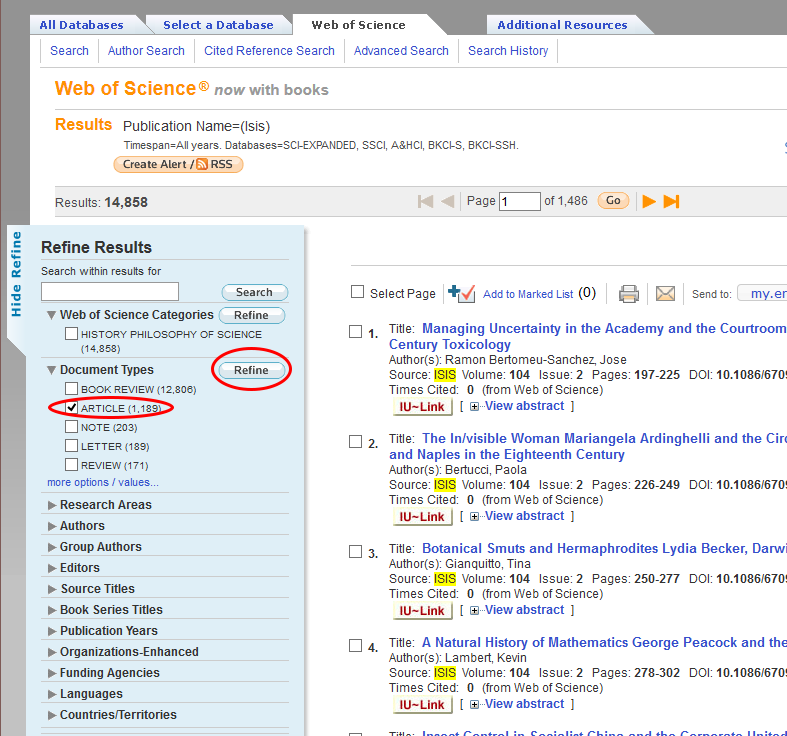
Figure 2: Isis periodical search results.
This is a list of every publication in the journal ISIS. Each individual record includes bibliographic material, abstract, and the list of references that are cited in the article. To get a reasonable dataset to work with, we’re going to download every article ever published in ISIS, of which there are 1,189. The rest of the records are book reviews, notes, etc. Select only the articles by clicking the checkbox next to ‘articles’ on the left side of the results screen and clicking ‘refine’.
The next step is to download all the records. This web service limits you to 500 records per download, so you’re going to need to download 3 separate files (records 1-500, 501-1000, and 1001-1189) and combine them together, which is a fairly complicated step, so pay close attention. There’s a little “Send to:” drop-down menu at the top of the search results (Figure 3). Click it, and click ‘Other File Formats’.
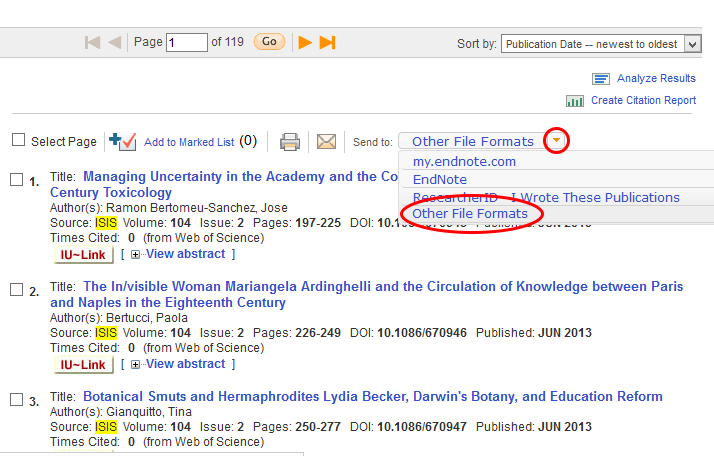
Figure 3: Saving Web of Science records.
At the pop-up box, check the radio box for records 1 to 500 and enter those numbers, change the record content to ‘Full Record and Cited References’, and change the file format to ‘Plain Text’ (Figure 4). Save the file somewhere you’ll be able to find it. Do this twice more, changing the numbers to 501-1000 and 1001-1189, saving these files as well.

Figure 4: Parameters for downloading Web of Science files.
You’ll end up with three files, possibly named: savedrecs.txt, savedrecs(1).txt, and savedrecs(2).txt. If you open one up (Figure 5), you’ll see that each individual article gets its own several-dozen lines, and includes information like author, title, keywords, abstract, and (importantly in our case) cited references.

Figure 5: An example ISIS record.

Figure 6: The end of an ISIS record file.
You’ll also notice (Figures 5 & 6) that first two lines and last line of every file are special header and footer lines. If we want to merge the three files so that the Sci2 Tool can understand it, we have to delete the footer of the first file, the header and footer of the second file, and the header of the last file, so that the new text file only has one header at the beginning, one footer at the end, and none in between. Those of you who are familiar enough with a text editor (and let’s be honest, it should be everyone reading this) go ahead and copy the three files into one huge file with only one header and footer. If you’re feeling lazy, just download it here.
Creating a Citation Network
Now open the Sci2 Tool (Figure 7) and go to File->Load in the drop-down menu. Find your super file with all of ISIS and open it, loading it as an ‘ISI flat format’ file (Figure 8).

Figure 7: The Sci2 Tool.
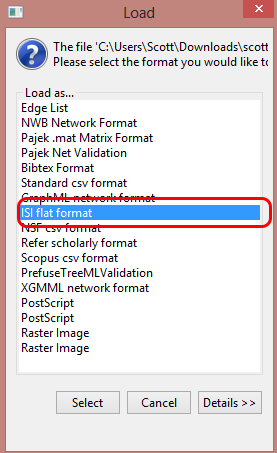
Figure 8: Loading a file as an ISI flat format file.
If all goes correctly, two new files should appear in the Data Manager, the pane on the right-hand side of the software. I’ll take a bit of a detour here to explain the Sci2 Tool.
The main ‘Console’ pane on the top-left will include a complete log of your workflow, including all the various algorithms you use, what settings and parameters you use with them, and how to cite the various ones you use. When you close the program, a copy of the text in the ‘Console’ pain will save itself as a log file in the program directory so you can go back to it later and see what exactly you did.
The ‘Scheduler’ pane on the bottom is just that: it shows you what algorithms are currently running and what already ran. You can safely ignore it.
Along with the drop-down menus at the top, the already-mentioned ‘Data Manager’ pane on the right is where you’ll be spending most of your time. Every time you load a file, it will appear in the data manager. Every time you run an algorithm on or manipulate that file in some way, a copy of it with the new changes will appear hierarchically nested below the original file. This is so, if you make a mistake, want to use an earlier version of the file, or want to run run a different set of analyses, you can still do so. You can right-click on files in the data manager to view or save them in various file formats. It is important to remember to make sure that the appropriate file is selected in the data manager when you run an analysis, as it’s easy to accidentally run an algorithm on some other random data file.
With that in mind, once your file is loaded, make sure to select (by left-clicking) the ‘1189 Unique ISI Records’ data file in the data manager. If you right-click and view the file, it should open up in Excel (Figure 9) or whatever your default *.csv viewer is, and you’ll see that the previous text file has been converted to a spreadsheet. You can look through it to see what the data look like.
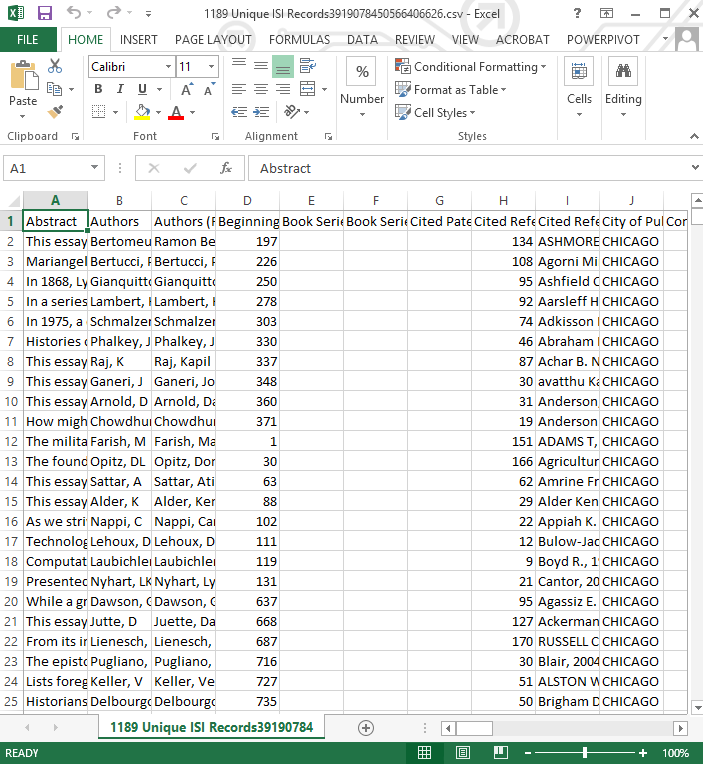
Figure 9: All of the ISIS History of Science journal articles as a csv.
When you’re done ogling at all the pretty data, close the spreadsheet and go back to the tool. Making sure the ‘1189 Unique ISI Records’ file is selected, go to ‘Data Preparation -> Extract Paper Citation Network’ in the drop-down menu.
Voilà! You now have a history of science citation network. The algorithm spits out two files: ‘Extracted paper-citation network’, which is the network file itself, and ‘Paper information’, which is a spreadsheet that includes all the nodes in the network (in this case, articles that either were published in ISIS or are cited by them). It includes a ‘localCitationCount’ column, which tells you how frequently a work is cited within the dataset (Shapin’s Leviathan and the Air Pump‘ is cited 16 times, you’ll see if you open up the file), and a ‘globalCitationCount’ column, which is how many times ISI Web of Science thinks the article has been cited overall, not just within the dataset (Merton’s ” The Matthew effect in science II” is cited 183 times overall). ‘globalCitationCount’ statistics are of course only available for the records you downloaded, so you have them for ISIS published articles, but none of the other records.
Select ‘Extracted paper-citation network’ in the data manager. From the drop-down menu, run ‘Analysis -> Networks -> Network Analysis Toolkit (NAT)’. It’s a good idea to run this on any network you have, just to see the basic statistics of what you’re working with. The details will appear in the console window (Figure 10).

Figure 10: Network analysis toolkit output on the ISIS citation network.
There are a few things worth noting right away. The first is that there are 52,479 nodes; that means that our adorable little dataset of 1,189 articles actually referenced over 50,000 other works between them, about 50 refs/article. The second fact worth noting is that there are 54,915 directed edges, which is the total number of direct citations in the dataset. One directed edge is a citation from a citing node (an ISIS article) to a cited node (either an ISIS article, or a book, or whatever the author decides to reference).
The last bit worth pointing out is the number of weakly connected components, and the size of the largest connected component. Each weakly connected component is a chunk of the network connected by citation chains: if article A and B are the only articles which cite article C, if article C cites nothing else, and if A and B are uncited by any other articles, they together make a weakly connected component. As soon as another citation link comes from or to them, it becomes part of that component. In our case, the biggest component is 46,971 nodes, which means that most of the nodes in the network are connected to each other. That’s important, it means history of science as represented by ISIS is relatively cohesive. There are 215 weakly connected components in all, small islands that are disconnected from the mainland.
If you have Gephi installed, you can visualize the network by selecting ‘Extracted paper-citation network’ in the data manager and clicking ‘Visualization -> Networks -> Gephi’, though what you do from there is beyond the scope of these instructions. It also probably won’t make a heck of a lot of sense: there aren’t many situations where visualizing a citation network are actually useful. It’s what’s called a Directed Acyclic Graph, which are generally the most visually boring graphs around (don’t cite me on this).
I do have a very important warning. You can tell it’s important because it’s bold. The Sci2 Tool was made by my advisor Katy Börner as a tool for people with similar research to her own, whose interests lie in modeling and predicting the spread of information on a network. As such, the direction of citation edges created by the tool are opposite what many expect. They go from the cited source to the citing source, because the idea is that’s the direction that information flows, rather than from the citing source to the cited source. As a historian, I’m more interested in considering the network in the reverse direction: citing to cited, as that gives more agency to the author. More details in the footnote. 2
Great, now that that’s out of the way, let’s get to the more interesting analyses. Select ‘Extracted paper-citation network’ in the data manager and run ‘Data Preparation -> Extract Document Co-Citation Network’. And then wait. Have you waited for a while? Good, wait some more. This is a process. And 50,000 articles is a lot of articles. While you’re waiting, re-read Networks Demystified 4: Co-Citation Analysis to get an idea of what it is you’re doing and why you want to do it.
Okay, we’re done (assuming you increased the allotted memory to the tool like we discussed earlier). You’re no presented the ‘Co-citation Similarity Network’ in the data manager, and you should, once again, run ‘Analysis -> Networks -> Network Analysis Toolkit (NAT)’ in the Data Manager. This as well will take some time, and you’ll see why shortly.

Figure 11: Network analysis toolkit of the ISIS co-citation network.
Notice that while there are the same number of nodes (citing or cited articles) as before, 52,479, the number of edges went from 54,915 to 2,160,275, a 40x increase. Why? Because every time two articles are cited together, they get an edge between them and, according to the ‘Average degree’ in the console pane, each article or book is cited alongside an average of 82 other works.
In order to make the analysis and visualization of this network easier we’re going to significantly cut its size. Recall that document co-citation networks connect documents that are cited alongside each other, and that the weight of that connection is increased the more often the two documents appear together in a bibliography. What we’re going to do here is drastically reduce the network’s size deleting any edge between documents unless they’ve been cited together more than once. Select ‘Co-citation Similarity Network’ and run ‘Preprocessing -> Networks -> Extract Edges Above or Below Value’. Use the default settings (Figure 12).
Note that when you’re doing a scholarly citation analysis, cutting all the edges below a certain value (called ‘thresholding’) is usually a bad idea unless you know exactly how it will affect your study. We’re doing it here to make the walkthrough easier.

Figure 12: Extracting edges to reduce the size of the network.
Run ‘Analysis -> Networks -> Network Analysis Toolkit (NAT)’ on the new ‘Edges above 1 by weight’ dataset, and note that the network has been reduced from two million edges to three thousand edges, a much more manageable number for our purposes. You’ll also see that there are 51,313 isolated nodes: nodes that are no longer connected to the network because we cut so many edges in our mindless rampage. Who cares about them? Let’s delete them too! Select ‘Edges above 1 by weight’ and run ‘Preprocessing -> Networks -> Delete Isolates’, and watch as fifty thousand precious history of science citations vanish in a puff of metadata. Gone.
If you run the Network Analysis Toolkit on the new network, you’ll see that we’re left with a small co-citation net of 1,166 documents and 3,344 co-citations between them. The average degree tells us that each document is connected to, on average, 6 other documents, and that the largest connected component contains 476 documents.
So now’s the moment of truth, the time to visualize all your hard work. If you know how to use Gephi, and have it installed, select ‘With isolates removed’ in the data manager and run ‘Visualization -> Networks -> Gephi’. If you don’t, run ‘Visualization -> Networks -> GUESS’ instead, and give it a minute to load. You will be presented with this stunning work of art vaguely reminiscent of last night’s spaghetti and meatball dinner (Figure 13).
Figure 13: GUESS in all its glory.
Fear not! The first step to prettifying the network is to run ‘Layout -> GEM’ and then ‘Layout -> Bin Pack’. Better already, right? Then you can make edits using the graph modifier below (or using python commands in the interpreter), but the friendly folks at my lab have put together a script for you that will do that automatically. Run ‘Script -> Run Script’.
When you do, you will be presented with a godawful java applet that automatically sticks you in some horrible temp directory that you have to find your way out of. In the ‘Look In:’ navigation drop-down, find your way back to your desktop or your documents directory and then find wherever you installed the Sci2 Tool. In the Sci2 directory, there’s a folder called ‘scripts’, and in the ‘scripts’ folder, there’s a ‘GUESS’ folder, and in the ‘GUESS’ folder you will find the holy grail. Select ‘reference-co-occurrence-nw.py’ and press ‘open’.
Magic! Your document co-citation network is now all green and pretty, and you can zoom in and out using either the +/- button on the left, or using your mouse wheel and clicking and dragging on the network itself. It’ll look a bit like Figure 14.

Figure 14: Co-Citation network in GUESS.
If you feel more dangerous and cool, you can try visualizing the same network in Gephi, and it might come out something like Figure 15.

Figure 15: Gephi’s document co-citation network, with nodes sized by how frequently they’re cited in ISIS. Click to enlarge.
That’s it! You’ve co-cited a dataset. I hope you feel proud of yourself, because you should. And all without breaking a sweat. If you want (and you should want), you can save your results by right clicking the various files in the data manager you want to save. I’d recommend saving the most recent file, ‘With isolates removed’, and saving it as an NWB file, which is fairly easy to read and is the Sci2 Tool’s native format.
Stay-tuned for the paradoxically earlier-numbered Networks Demystified 6, on organizing your twitter feed.
Notes:
- Part 4 also links to a few great tutorials on how to do this with programming, but if you don’t know the first thing about programming, start here instead. ↩
- Those of you who know network basics, keep this in mind when running your analyses: PageRank, In & Out Degree, etc., may be opposite of what you expect, with the papers that cite the most sources as those with the highest In-Degree and PageRank. If this is opposite your workflow, you can fairly easily change the data by hand in a spreadsheet editor or with regular expressions. ↩
Dear Scott,
I really enjoy your bloggs. Can I ask a couple of questions?
I work with relatively small networks – e.g. anything that deals with Language and Alzheimer’s Disease. I get networks that look like your figure 13. Normally they resolve into nice clusters when I run the lay-out program in Gephi, but the Alzheimer’s data doesn’t do that. Gephi just identifies a single community. After a lot of fiddling around, I think the reason for this is that a large proportion of the authors in my data set are cited by everybody. I’ve also found this in some geological data sets. If I remove these highly connected nodes, then the remaining items do resolve into communities, so I get a kind of donut effect. My questions are:
a) are you familiar with this as a problem, or am I just being unlucky with my data sets?
b) if it is a familiar problem, is there a standard way of dealing with it?
Give my regards to Katy Borner. We met at the Summer School in Leuven a couple of years ago.
Thank you for the kind words, Paul.
This is a familiar problem, but while the methods for dealing with it have become standardized, I’m not entirely convinced they’re the right way to go about things. Usually, what people will do is threshold edges, so that edges below a certain number (say, if a paper isn’t cited alongside another at least, say, twice, we don’t show the connection between them. For most extremely dense co-citation networks, due to the hockey-puck nature of edge weight distributions, usually thresholding by removing only those edges of weight 1 is sufficient.
That said, I think this is a wrong-minded approach intended to get data that perhaps shouldn’t be analyzed this way to fit into a pre-existing analysis. This is not uncommon in scientometrics; co-authorship analysis, for example, tends not to work well for humanities data because humanists don’t co-author, nor for particle physicists because they co-author with thousands of others on a single paper, yet you’ll still see this analysis run on both groups, with a few tweaks to make it work better.
In general, if the basic analysis doesn’t work, I’d recommend trying to find another axis of analysis which is more suitable for the data. In this instance in particular, I don’t think thresholding is such a sin, but if you start needing to threshold beyond weight 2, you’re probably just artificially splitting a community that should be unified.
Thanks for your reply, Scott.
The specific problem I have is a bit different from the one you solved by thresholding edges. My problem is that I have data where almost all the papers in my data set cite the same half a dozen sources, so if N is the number of nodes in my data set, I have half a dozen or so nodes with degree of N-1. This leads Gephi to find a single cluster in the data. It seems to me that these nodes don’t discriminate other items in the data set – so I’ve been experimenting with removing them before I do the modularity analysis. If I do this, then I get several clusters, as expected.
My question is whether this procedure makes sense. In effect, I’m creating an artificial cluster that includes all the massively cited nodes, and a donut of lesser authors around this cluster. The real variation is to be found in the donut rather than in the centre. Is this a problem that other people have noted?
I can send you some pictures if this isn’t clear.
Paul Meara
Ah, I see what you mean, interesting! Are you running a co-citation analysis, or a direct citation analysis?
The issue here is that everything is connected to the same set of canonical works, and so if they form their own communities, those communities are not visible due to all of them being so closely connected to the canon. If every article in your set cites the same 12 sources, they would all be connected to each other via an edge of weight 12 if you ran a co-citation analysis.
This is not something I have personally encountered, because the datasets I use tend to be much larger, but it certainly is a conundrum. I can’t speak to any standard solutions, but my first notion if I’d come across this problem would be to try to create some sort of tf-idf (http://en.wikipedia.org/wiki/Tf%E2%80%93idf) type score for citations, pretending each citation is a ‘word’, and filtering out those words which are common to all documents. Much like what you described.
That said, if your set of canonical works is too large, what you find in your donut may be so small that you can’t be sure whether your communities are real, or due to random chance. That depends on your data. I think as long as you’re clear in your write-up that you’re looking for the more subtle communities forming outside the canon, and that what connects them all together is stronger than the smaller communities that set them apart, you should be on fine ground.
Hi Scott, Thanks for your instructions. It’s really helpful. I was trying to find out the Main Path from my network using Gephi or Guess. I realized that Gephi doesn’t have the Search Path Linc Count algorithm installed in it. That’s really not helpful for me because without this algorithm I can’t do the Main Path Analysis. Is it possible using Sci2 and Guess to conduct Main Path Analysis? Thanks in advance.
Neil
Hi Neil, unfortunately none of those software packages can do Main Path Analysis – you’ll need to use pajek for that. There’s also CitNetExplorer, a new tool which does Transitive Reduction, a related algorithm.
hi Scott, I am struggling with the first hurdle of getting the ‘Full Record and Cited References’. When I go to save to other file type I only get the options for author, title, source? Is this a limitation of my institution subscription or is it simply that ISI have removed/moved the feature?
It sounds like you’re not searching the Web of Science core dataset, but one of the many Web of Knowledge datasets. You have to make sure the only database you’re searching through is the “Web of Science Core Collection,” and then it should work fine.
Thanks Scott, I tried refining by dataset but still only get the same options. It appears that you need to select the dataset before the search is run. Not immediately intuitive from the new interface. Thanks again for your help!
How do you deal with duplicate citations? I generated the “Extracted paper-citation network” but then I have to manually correct for duplicate nodes (if I use “Detect Duplicate Nodes” I don’t have optimal results).
Is there a way to insert the manually correct file (.csv) into Sci2 ? (I tried to copy and paste but it did not work)
Thanks for your help!
Thanks Scott!! You are the best! save my day, my week, and probably my thesis!
Darn, they changed the options in Web of Science, I can’t download the citations as part of the export of the plain text of references. My main interest is figuring out how to get citations without having to rely on crappy OCR tool in Adobe Acrobat. Any ideas?
Hi, the biggest thank you for you post. But two questions. After you loaded your data in sci2, you get csv file where all column are separated, but when i loaded file isis_record.txt in ISI format, i see nonstructured view. i did screen. How get separate columns like you have,
http://i66.fastpic.ru/big/2015/1019/ea/7ddd59ebe7724e7f58f1a5cf74c05dea.jpg
and second question
i extracted paper-citation network, and when i go to Analysis – network-network analysis toolkit i see this error
unexpected error occurred while the exictung algorithm NAT
java.lang.NumberFormatException: For input string: “2,0928”
at sun.misc.FloatingDecimal.readJavaFormatString(Unknown Source)
at sun.misc.FloatingDecimal.parseDouble(Unknown Source)
at java.lang.Double.parseDouble(Unknown Source)
at edu.iu.nwb.toolkit.networkanalysis.analysis.NodeStats.getRoundedAverageDegree(NodeStats.java:89)
at edu.iu.nwb.toolkit.networkanalysis.analysis.NetworkProperties.averageDegreeInfo(NetworkProperties.java:106)
at edu.iu.nwb.toolkit.networkanalysis.analysis.NetworkProperties.calculateNetworkProperties(NetworkProperties.java:43)
at edu.iu.nwb.toolkit.networkanalysis.ToolkitAlgorithm.execute(ToolkitAlgorithm.java:50)
at org.cishell.reference.gui.menumanager.menu.AlgorithmWrapper.tryExecutingAlgorithm(AlgorithmWrapper.java:308)
at org.cishell.reference.gui.menumanager.menu.AlgorithmWrapper.execute(AlgorithmWrapper.java:175)
at org.cishell.reference.app.service.scheduler.AlgorithmTask.run(SchedulerServiceImpl.java:643)
at java.lang.Thread.run(Unknown Source)
You are my HERO! thank you <3 <3
<3 <3
How to use Pajek for Main Path analysis? I am exploring the software but always receiving the error that network is not acyclic!.
Thanks in advance.
Often large citation networks are not DAGs (Directed Acyclic Graphs) because, especially recently, you have articles that cite forward in time. For example, if your article A cites an article preprint B, and then in their final publication they in turn cite your new article A, you suddenly have a cycle in the graph. Main Path Analysis only works on DAGs, so if you want to run that algorithm, you’ll have to remove the instances in your citation network where cycles occur (forward-citations).
Thanks for your prompt response. I want to know that which software should I choose to perform citation analysis? Actually, I want to use data generated from Scopus database.