I wrote this in 2012 in response to a twitter conversation with Mike Taylor, who was patient enough to read a draft of this post in late November and point out all the various ways it could be changed and improved. No doubt if I had taken the time to take his advice and change the post accordingly, this post would be a beautiful thing and well-worth reading. I’d like to thank him for his patient comments, and apologize for not acting on them, as I don’t foresee being able to take the time in the near future to get back to this post. I don’t really like seeing a post sit in my draft folder for months, so I’ll release it out to the world as naked and ugly as the day it was born, with the hopes that I’ll eventually sit down and write a better one that takes all of Mike’s wonderful suggestions into account. Also, John Kruschke apparently published a paper with a similar title; as it’s a paper I’ve read before but forgot about, I’m guessing I inadvertently stole his fantastic phrase. Apologies to John!
——————–
I recently [okay, at one point this was ‘recent’] got in a few discussions on Twitter stemming from a tweet about p-values. For the lucky and uninitiated, p-values are basically the go-to statistics used by giant swaths of the academic world to show whether or not their data are statistically significant. Generally, the idea is that if the value of p is less than 0.05, you have results worth publishing.
Introducing p-values
There’s a lot to unpack in p-values; a lot of history, of a lot of baggage, and a lot of reasons why it’s a pretty poor choice for quantitative analysis. I won’t unpack all of it, but I will give a brief introduction to how the statistic works. At its simplest, according to Wikipedia, “the p-value is the probability of obtaining a test statistic at least as extreme as the one that was actually observed, assuming that the null hypothesis is true.” No, don’t run away! That actually makes sense, just let me explain it.
We’ll start with a coin toss. Heads. Another: tails. Repeat: heads, heads, tails, heads, heads, heads, heads, tails. Tally up the score, of the 10 tosses, 7 were heads and 3 were tails. At this point, if you were a gambler, you might start guessing the coin is weighted or rigged. I mean, seriously, you toss the coin 10 times and only 3 of those were tails? What’s the probability of that, if the coin is fair?
That’s exactly what the p-value is supposed to tell us; what’s the probability of getting 3 or fewer tails out of 10 coin tosses, assuming the coin is fair? That assumption that the coin is fair is what statisticians call the null hypothesis; if we show that it’s less than 5% likely (p < 0.05) that the we’d see 3 or fewer tails in 10 coin flips, assuming a fair coin, statisticians tell us we can safely reject the null hypothesis. If this were a scientific experiment, we’d say that because p < 0.05, our results are significant; we can reject the null hypothesis that the coin is a fair one, because it’s pretty unlikely that the experiment would have turned out this way if the coin was fair. Huzzah! Callooh! Callay! We can publish our findings that this coin just isn’t fair in the world-renowned Journal of Trivial Results and Bad Bar Bets (JTRB3).
So how is this calculated? Well, the idea is that we have to look at the universe of possible results given the null hypothesis; that is, if I had a coin that was truly fair, how often will the result of my flipping it yield 7 heads and 3 tails? Obviously, given a fair coin, most scenarios will yield about a 50/50 split on heads and tails. It is, however, not completely impossible for us to get our 7/3 results. What we have to calculate is, if we flipped a fair coin in an infinite amount of experiments, what percent of those experiments would give us 7 heads and 3 tails? If it’s under 5%, p < 0.05, we can be reasonably certain that our result probably implies a stacked coin. We can assume that because in only 5% of experiments on a fair coin will the results look like the results we see.
We use 0.05, or 5%, mostly out of a long-standing social agreement. The 5% mark is low enough that we can reject the null hypothesis beyond most reasonable doubts. That said, it’s worth remembering that the difference between 4.9% and 5.1% is itself often not statistically significant, and though 5% is our agreed upon convention, it’s still pretty arbitrary. The best thing anyone’s ever written to this point was by Rosnow & Rosenthal (1989):
“We are not interested in the logic itself, nor will we argue for replacing the .05 alpha with another level of alpha, but at this point in our discussion we only wish to emphasize that dichotomous significance testing has no ontological basis. That is, we want to underscore that, surely, God loves the .06 nearly as much as the .05. Can there be any doubt that God views the strength of evidence for or against the null as a fairly continuous function of the magnitude of p?”
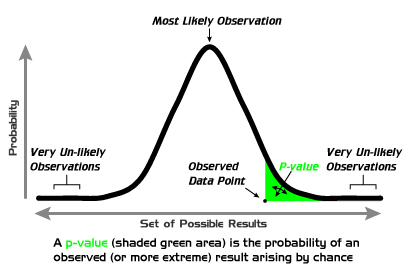
How p-values work. via wikipedia.
{kind=link}
I’m really nailing this point home because p-values are so often misunderstood. Wikipedia lists seven common misunderstandings of p-values, and I can almost guarantee that a majority of scientists who use the statistic are guilty of at least some of them. I’m going to quote the misconceptions here, because they’re really important.
- The p-value is not the probability that the null hypothesis is true.
In fact, frequentist statistics does not, and cannot, attach probabilities to hypotheses. Comparison of Bayesian and classical approaches shows that a p-value can be very close to zero while the posterior probability of the null is very close to unity (if there is no alternative hypothesis with a large enough a priori probability and which would explain the results more easily). This is Lindley’s paradox.- The p-value is not the probability that a finding is “merely a fluke.”
As the calculation of a p-value is based on the assumption that a finding is the product of chance alone, it patently cannot also be used to gauge the probability of that assumption being true. This is different from the real meaning which is that the p-value is the chance of obtaining such results if the null hypothesis is true.- The p-value is not the probability of falsely rejecting the null hypothesis. This error is a version of the so-called prosecutor’s fallacy.
- The p-value is not the probability that a replicating experiment would not yield the same conclusion. Quantifying the replicability of an experiment was attempted through the concept of P-rep (which is heavily criticized)
- 1 − (p-value) is not the probability of the alternative hypothesis being true (see (1)).
- The significance level of the test (denoted as alpha) is not determined by the p-value.
The significance level of a test is a value that should be decided upon by the agent interpreting the data before the data are viewed, and is compared against the p-value or any other statistic calculated after the test has been performed. (However, reporting a p-value is more useful than simply saying that the results were or were not significant at a given level, and allows readers to decide for themselves whether to consider the results significant.)- The p-value does not indicate the size or importance of the observed effect (compare with effect size). The two do vary together however – the larger the effect, the smaller sample size will be required to get a significant p-value.
One problem with p-values (and it often surprises people)
Okay, I’m glad that explanation is over, because now we can get to the interesting stuff, and they’re all based around assumptions. I worded the above coin-toss experiment pretty carefully; you keep flipping a coin until you wind up with 7 heads and 3 tails, 10 flips in all. The experimental process seems pretty straight forward: you flip a coin a bunch of times, and record what you get. Not much in the way of underlying assumptions to get in your way, right?
Wrong. There are actually a number of ways this experiment could have been designed, each yielding the same exact observed data, but each as well yielding totally different p-values. I’ll focus on two of those possible experiments here. Let’s say we went into the experiment saying “Alright, coin, I’m going to flip you 10 times, and then count how often you land on heads and how often you land on tails.” That’s probably how you assumed the experiment was run, but I never actually described it like that; all I said was you wound up flipping a coin 10 times, seeing 7 heads and 3 tails. With that information, you can also have said “I’m going to flip this coin until I see 3 tails, and then stop.” If you remember the sequence above (heads, tails, heads, heads, tails, heads, heads, heads, heads, tails), that experimental design also fits our data perfectly. We kept flipping a coin until we saw 3 tails, and in the interim, we also observed 7 heads.
The problem here is in how p-values work. When you ask what the probability is that your result came from chance alone, a bunch of assumptions underlie this question, the key one here being the halting conditions of your experiment. Calculating how often 10 coin-tosses of a fair coin will result in a 7/3 split (or 8/2 or 9/1 or 10/0) will give you a different result than if you calculated how often waiting until the third tails will give you a 7/3 split (or 8/3 or 9/3 or 10/3 or 11/3 or 12/3 or…). The space of possibilities changes, the actual p-value of your experiment changes, based on assumptions built into your experimental design. If you collect data with one set of halting conditions, and it turns out your p-value isn’t as low as you’d like it to be, you can just pretend you went into your experiment with different halting conditions and, voila!, your results become significant.
The moral of the story is that p-values can be pretty sensitive to assumptions that are often left unspoken in an experiment. The same observed data can yield wildly different values. With enough mental somersaults regarding experimental assumptions, you can find that a 4/6 split in a coin toss actually resulted from flipping a coin that isn’t fair. Much of statistics is rife with unspoken assumptions about how data are distributed, how the experiment is run, etc. It is for this reason that I’m trying desperately to get quantitative humanists using non-parametric and Bayesian methods from the very beginning, before our methodology becomes canonized and set. Bayesian methods are also, of course, rife with assumptions, but at least most of those assumptions are made explicit at the outset. Really, the most important thing is to learn not only how to run a statistic, but also what it means to do so. There are appropriate times to use p-values, but those times are probably not as frequent as is often assumed.
Hi, Thanks for the post.
I am looking forward for part 2.
A great article that is well written.
Hear hear!
For folks wanting more about the perfidy of p values, see http://www.indiana.edu/~kruschke/articles/Kruschke2012JEPG.pdf
Scott, I’m glad you don’t have copy editors un-contracting contractions like “don’t” in the phrase “friends don’t let friends,” as they did for the section header on the second page of this article: http://www.indiana.edu/~kruschke/articles/Kruschke2010TiCS.pdf
But the phrase does sound much more high-brow (even British) to say, “friends do not let friends” …
Keep up the good work!
You know, I probably read that article at some point and unconsciously stole that wonderful subtitle – sorry! I’ll have to update the post with an unintentional attribution credit. Thanks for the encouragement and the link to more information!
I probably subsconsciously picked it up from someone else! I was merely the one who had the temerity to put it in an article Like this article, which has a header: “The road to NHST is paved with good intentions” http://www.indiana.edu/~kruschke/articles/Kruschke2010WIRES.pdf
Like this article, which has a header: “The road to NHST is paved with good intentions” http://www.indiana.edu/~kruschke/articles/Kruschke2010WIRES.pdf
Can you recommend more information — ideally practically-focused and accessible — on the sorts “non-parametric and Bayesian methods” you recommend?
Absolutely! For Bayesian methods, John Kruschke’s textbook Doing Bayesian Data Analysis is a great intro to methods which assumes no prior knowledge in stats and is very practically focused, with R tutorials and sample programs, and lots of applications (for psychology, but easily transferable) http://www.indiana.edu/~kruschke/DoingBayesianDataAnalysis/
For nonparametric stats, I’ve heard Practical Nonparametric Statistics (any edition) is good, though I haven’t picked it up myself. Any other suggestions out there? http://www.wiley.com/WileyCDA/WileyTitle/productCd-0471160687.html
what happens when your termination condition is “when the formula for the p value says I can stop”??
Sounds like you’ve stumbled on the right formula for achieving significance, moto!
That falls under “sampling to a foregone conclusion”. For an overview, watch at 3:25 into this video: http://youtu.be/YyohWpjl6KU
You can make that work, moto. See http://elem.com/~btilly/ab-testing-multiple-looks/part1-rigorous.html for a procedure that calculates a p-value that is accurate even with constantly looking. However it is impractical in the real world, and the followup article explains why. (I do intend to finish that series some day.)
Scott,
Well said. This is a hard topic to explain and you have done a great job. I teach p-values to students I tutor at http://graduatetutor.com/ and will be happy to take a shot at incorporating Mike Taylor’s feedback into the article (not sure if it will live up to your expectations but worth a try) or wonder if we can get a great piece on p values if you open it up – open source/wikipedia type it!
Senith, you’re more than welcome to build on and edit this tutorial as you like! I publish everything in this blog under a cc-by license.
Here’s a great paper explaining the misconceptions underlying the popularity of p-values, and the history thereof: http://annals.org/article.aspx?articleid=712762
As a wet-bench experimental scientist, I find it amazing how often experiments, especially experiments using animals, that report a particular result with a p value of 0.05 or (usually) less do not repeat.
You made one of the errors interpreting the p-value (error 2 in the list you quote from Wikipedia) when, in the second-last paragraph, you said “When you ask what the probability is that your result came from chance alone, “
Well that’s embarrassing! Thanks for catching the mix-up. Haven’t the foggiest idea what I was thinking two years ago that made me write that.